在当今数据驱动的决策环境中,埋点数据是理解用户行为、优化产品体验的基石。从用户的一次点击、一次浏览到一次购买,这些看似微小的行为都被精心设计的埋点捕获,转化为原始数据流。原始数据本身并无价值,只有经过系统化、专业化的数据处理,才能提炼出驱动业务增长的洞察。本文将探讨埋点数据的处理流程、核心挑战与最佳实践。
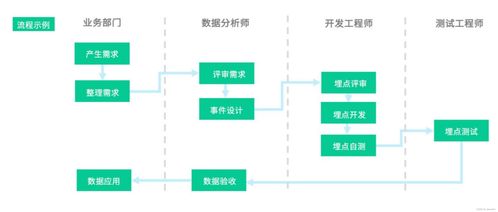
数据处理始于埋点方案的严谨设计。一个清晰的埋点规范是后续所有工作的前提,它需要明确定义每个事件(Event)的名称、属性(Properties)以及触发时机。例如,“加入购物车”事件应包含商品ID、价格、数量等属性。混乱的埋点设计会导致数据“脏乱差”,使后续清洗成本激增。因此,数据团队需要与产品、研发部门紧密协作,确保埋点采集的准确性与一致性。
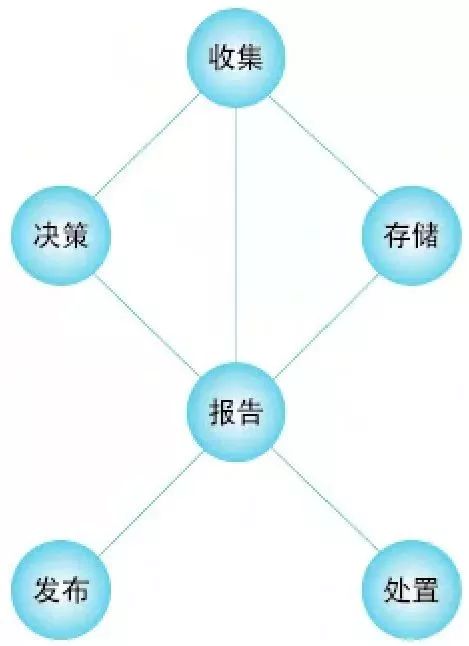
当海量埋点数据涌入数据管道,数据处理的核心阶段便随之展开。这一过程通常包含几个关键步骤:
- 数据采集与传输:数据通过SDK从客户端(Web、App等)或服务器发出,经由日志收集系统(如Apache Kafka)实时或批量传输到数据仓库(如Hadoop HDFS、云存储等)。确保传输的稳定、低延迟与不丢失是此环节的重中之重。
- 数据清洗与解析:原始日志通常是半结构化或非结构化的JSON字符串。此步骤需要将其解析、展开,并清洗掉无效数据(如空值、测试数据、格式错误的数据)。例如,过滤掉内部员工的访问日志,矫正异常的时间戳。
- 数据建模与整合:清洗后的数据被按照主题(如用户、商品、流量)组织成易于理解的数据模型(如星型模型、维度建模)。这一步将分散的埋点事件与业务数据库中的用户信息、商品信息等进行关联整合,形成完整的用户行为旅程视图。
- 数据存储与计算:处理后的数据存入适合分析的数据仓库或数据湖(如Snowflake, BigQuery, ClickHouse)。在此之上,通过SQL或大数据计算引擎(如Spark, Flink)进行聚合计算,生成每日活跃用户(DAU)、转化漏斗、用户留存率等关键指标。
- 数据可视化与洞察:数据通过BI工具(如Tableau, Looker, 国内如FineBI)以报表或仪表盘的形式呈现给业务人员。分析师可以基于此进行深度挖掘,回答诸如“新改版功能是否提升了转化?”等业务问题。
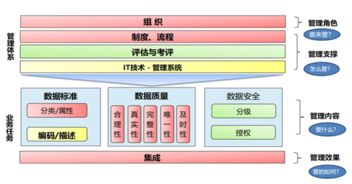
在整个流程中,数据质量监控与数据治理是贯穿始终的生命线。需要建立自动化的数据质量校验规则,监控数据量的异常波动、字段取值的分布是否合理,并及时告警。建立统一的数据字典和指标口径,避免“数据孤岛”和指标歧义。
面对日益复杂的业务场景和严格的隐私法规(如GDPR、个人信息保护法),数据处理也面临着巨大挑战。如何在数据采集阶段做好匿名化与脱敏,如何在数据处理流程中确保安全合规,成为技术与管理并重的课题。
埋点数据的处理绝非简单的技术堆砌,而是一个将原始行为“矿石”冶炼成决策“黄金”的系统工程。它要求技术上的严谨可靠,更要求对业务的深刻理解。只有构建起高效、稳健、可信的数据处理流水线,埋点所蕴含的巨大价值才能真正释放,成为企业智能化运营的核心引擎。