在数据科学和气象研究的交叉领域,Jupyter Notebook已成为一个不可或缺的工具,它以其交互性、可视化和可重复性,极大地简化了气象数据的分析处理流程。本文将以一个典型的气象数据集为例,详细阐述在Notebook环境中进行数据加载、清洗、探索性分析和基础可视化的完整过程。
一、环境搭建与数据加载
我们创建一个新的Jupyter Notebook,并导入必要的Python库:pandas用于数据处理,numpy用于数值计算,matplotlib和seaborn用于数据可视化。气象数据通常以CSV、NetCDF等格式存储。这里假设我们有一个名为weather<em>data.csv的文件,包含日期、温度、湿度、降水量、风速等字段。使用pandas的read</em>csv函数可以轻松加载数据:import pandas as pd<br />weather<em>df = pd.read</em>csv('weather<em>data.csv')
加载后,通过weather</em>df.head()和weather_df.info()快速查看数据的前几行、列名、数据类型及缺失值情况。
二、数据清洗与预处理
原始数据往往存在缺失值、异常值或格式不一致的问题。我们需要进行清洗以确保分析质量。
- 处理缺失值:可以使用
weather<em>df.isnull().sum()统计各列缺失值数量。对于少量缺失,可采用向前/向后填充(ffill/bfill)或插值法;对于大量缺失,可能需要删除该列或使用均值/中位数填充。例如,对温度列用前值填充:weather</em>df['temperature'].fillna(method='ffill', inplace=True)。 - 格式转换:确保日期列被正确解析为datetime格式:
weather<em>df['date'] = pd.to</em>datetime(weather<em>df['date']),并可以将其设为索引以便时间序列分析:weather</em>df.set_index('date', inplace=True)。 - 处理异常值:通过描述性统计(
weather_df.describe())或箱线图识别异常值,并根据业务逻辑进行修正或删除。
三、探索性数据分析(EDA)
清洗后的数据可以进行深入的探索,以发现潜在的模式和关系。
- 描述性统计:计算关键气象指标(如平均温度、最高风速、总降水量)的基本统计量。
- 时间趋势分析:对温度、降水量等变量进行重采样,例如计算月度平均温度:
monthly<em>avg</em>temp = weather_df['temperature'].resample('M').mean(),并用折线图可视化其长期变化趋势。 - 变量间关系:使用散点图矩阵或热力图探索温度、湿度、风速等变量之间的相关性。例如,计算相关系数矩阵:
correlation<em>matrix = weather</em>df.corr(),并用seaborn.heatmap可视化。
四、基础可视化
可视化是理解气象数据的重要手段。在Notebook中,我们可以内联显示图表。
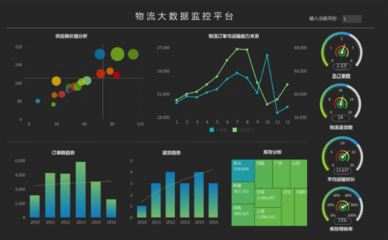
1. 折线图:展示温度随时间的变化,可清晰看出日变化或季节趋势。
2. 柱状图:比较各月的总降水量,直观呈现降水分布。
3. 箱线图:分析不同季节风速的分布情况,识别异常天气。
4. 直方图:查看湿度的频率分布,了解其集中趋势。
这些图表可以通过matplotlib.pyplot或seaborn库轻松实现,并添加标题、坐标轴标签以增强可读性。
五、结论与进一步方向
通过上述步骤,我们完成了对气象数据的基本处理与分析,初步揭示了数据中的规律,如温度的季节性波动、降水与湿度的正相关等。在Jupyter Notebook中,整个流程被记录为代码、输出和注释的有机组合,确保了分析的可重复性和可扩展性。可以在此基础上进行更复杂的分析,如时间序列预测(使用ARIMA或LSTM模型)、极端天气事件检测或结合地理信息进行空间分析。Notebook的交互特性使得迭代和分享分析结果变得异常便捷,是气象数据分析处理的理想起点。